
Learning to Learn with Probabilistic Task Embeddings
To operate successfully in a complex and changing environment, learning agents must be able to acquire new skills quickly. Humans display remarkable skill in this area — we can learn to recognize a new object from one example, adapt to driving a different car in a matter of minutes, and add a new slang word to our vocabulary after hearing it once. Meta-learning is a promising approach for enabling such capabilities in machines. In this paradigm, the agent adapts to a new task from limited data by leveraging a wealth of experience collected in performing related tasks. For agents that must take actions and collect their own experience, meta-reinforcement learning (meta-RL) holds the promise of enabling fast adaptation to new scenarios. Unfortunately, while the trained policy can adapt quickly to new tasks, the meta-training process requires large amounts of data from a range of training tasks, exacerbating the sample inefficiency that plagues RL algorithms. As a result, existing meta-RL algorithms are largely feasible only in simulated environments.
The lustre of off-policy meta-RL
 While policy gradient RL algorithms can achieve high performance on complex high-dimensional control tasks (e.g., controlling a simulated humanoid robot to
While policy gradient RL algorithms can achieve high performance on complex high-dimensional control tasks (e.g., controlling a simulated humanoid robot to
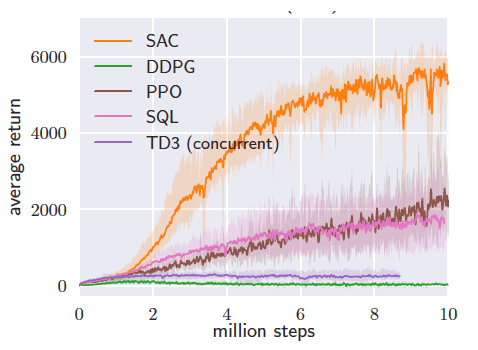
run), they are woefully sample inefficient. For example, the state-of-the-art policy gradient method PPO requires 100 million samples to learn a good policy for humanoid. If we were to run this algorithm on a real robot, running continuously with a 20 Hz controller and without counting time for resets, it would take nearly two months to learn this policy. This sample inefficiency is largely because the data to form the policy gradient update must be sampled from the current policy, precluding the re-use of previously collected data during training. Recent off-policy algorithms (TD3, SAC) have matched the performance of policy gradient algorithms while requiring up to 100X fewer samples. If we could leverage these algorithms for meta-RL, weeks of data collection could be reduced to half a day, putting meta-learning within reach of our robotic arms. Off-policy learning offers further benefits beyond better sample efficiency when training from scratch. We could also make use of previously collected static datasets, and leverage data from other robots in other locations.
Source: K. Rakelly, “BAIR: Berkley Artificial Intelligence Research,” June 10, 2019.
https://bair.berkeley.edu/blog/2019/06/10/pearl/
Task: RA1.A1: The Swarm’s Knowledge Base: Contextual Perceptual Representations

